
I'm currently an AI and speech algorithm designer at Goodix Technology. From 2017 to 2021, I had been a doctoral researcher at the Electrical Engineering Department (ESAT), in the research group of Stadius Center for Dynamical Systems, Signal Processing, and Data Analytics (STADIUS) under the supervision of Prof. Toon van Watershoot, Prof. Luc Geurts and Prof. Peter Kuppens, in KU Leuven, Belgium. In 2015 and 2016, I received two M.Sc. degrees in Electronics Engineering and in Artificial Intelligence, respectively, from KU Leuven, Belgium. My research is focusing on speech and audio processing with deep learning, speech emotion recognition, real-time deep learning for edge devices.
Publications
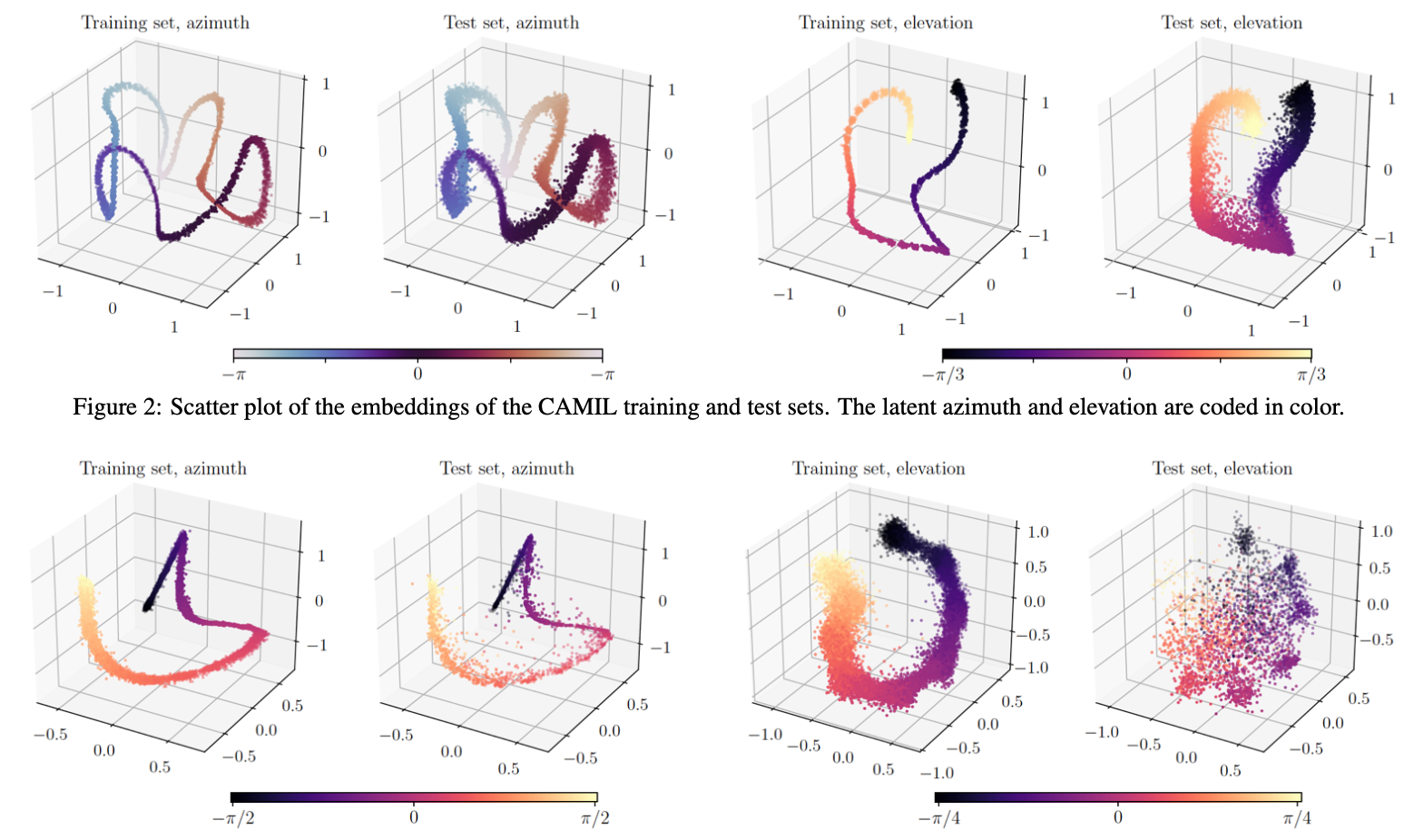
Frontiers in Neuroinformatics 2022
Towards Learning Robust Contrastive Embeddings For Binaural Source Localization
Duowei Tang, Maja Taseska, and Toon van Waterschoot
Proposes a weakly-supervised contrastive embedding framework for binaural sound source localization, where a neural network learns low-dimensional representations of binaural cues that preserve spatial proximity, showing robustness to reverberation, noise, and limited training data.
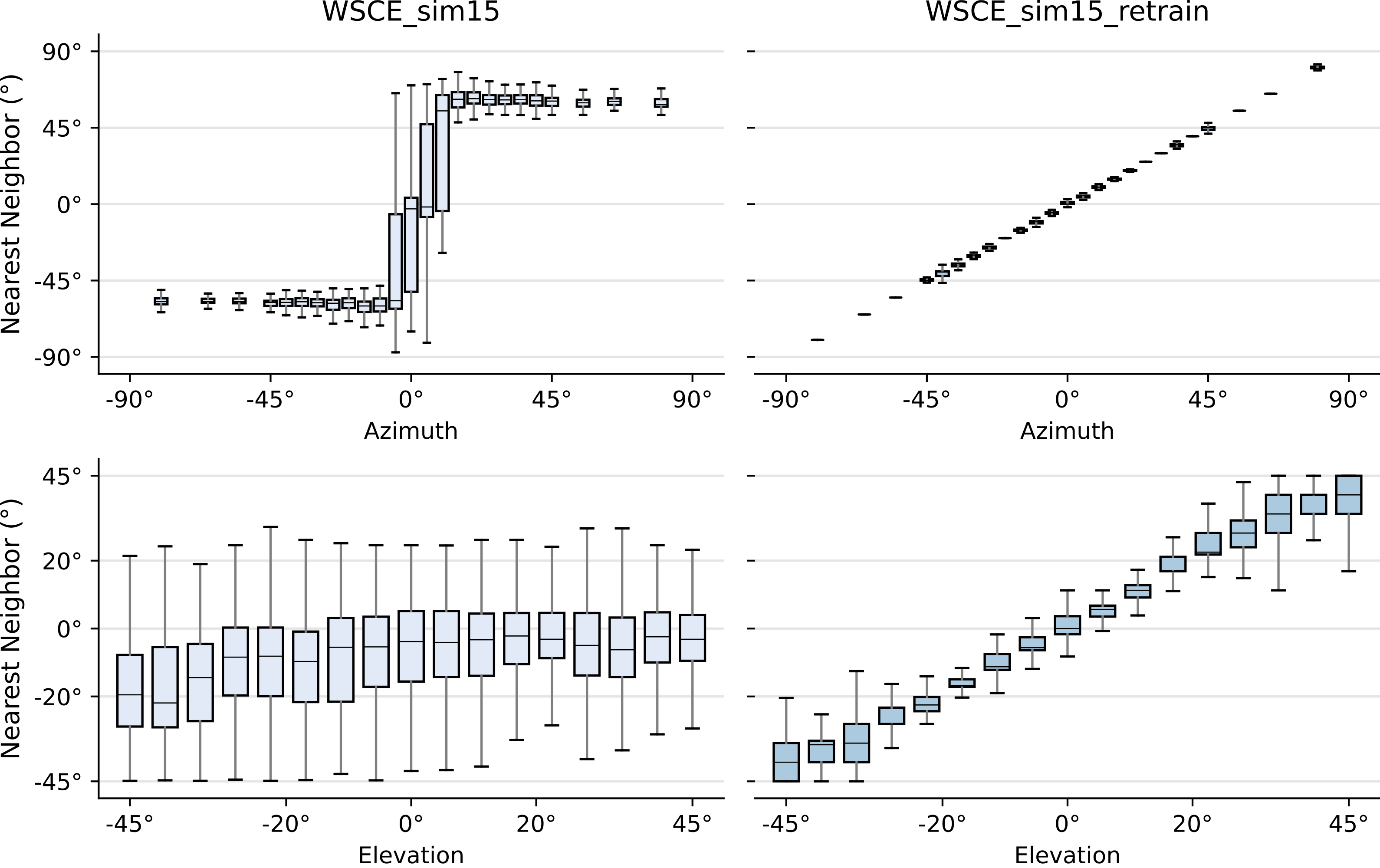
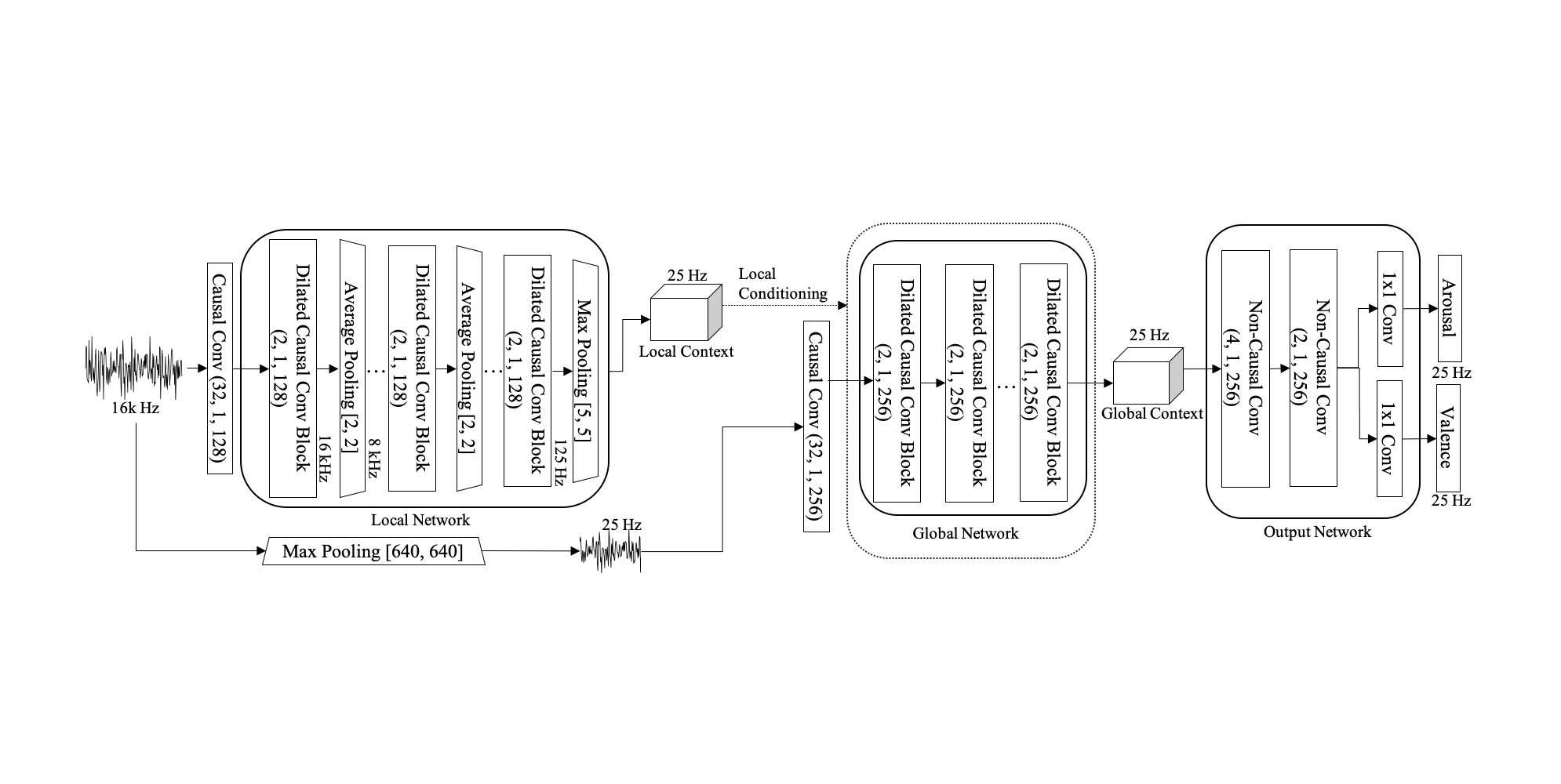
EURASIP Journal on Audio, Speech, and Music Processing 2021
End-to-end speech emotion recognition using a novel context-stacking dilated convolution neural network
Duowei Tang, Peter Kuppens, Luc Geurts, and Toon van Waterschoot
Proposes an end-to-end speech emotion recognition system using dilated convolutional neural networks with context stacking (DiCCOSER-CS), which eliminates recurrent layers while achieving superior performance to LSTM-based models through its large receptive field and parallelizable architecture, demonstrating improved accuracy on both regression (arousal/valence prediction) and classification tasks.
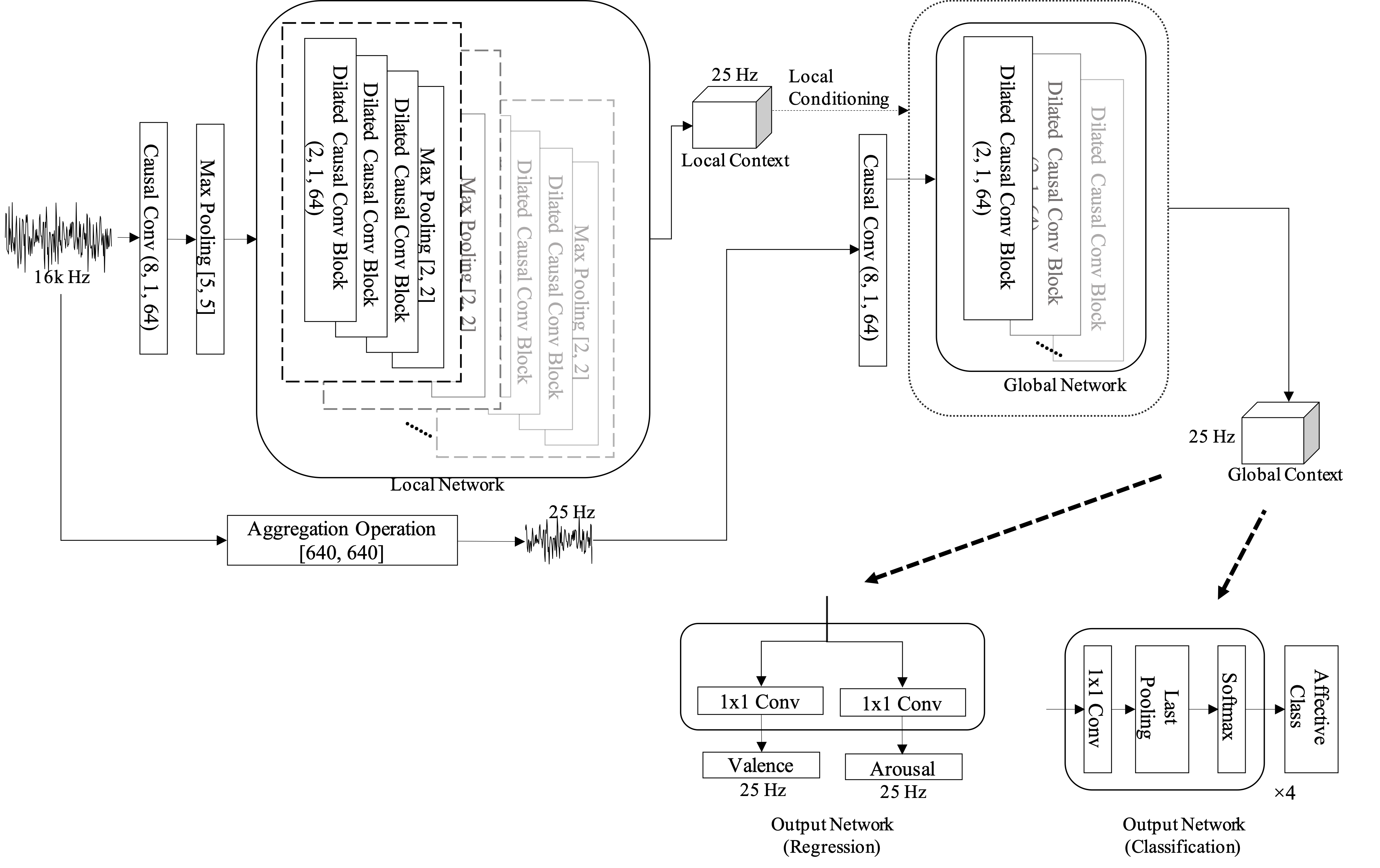
28th European Signal Processing Conference (EUSIPCO) 2020
Adieu recurrence? End-to-end speech emotion recognition using a context stacking dilated convolutional network
Duowei Tang, Peter Kuppens, Luc Geurts, and Toon van Waterschoot
Proposes a fully convolutional end-to-end speech emotion recognition model using dilated causal convolutions and context stacking, eliminating recurrent layers while outperforming LSTM-based approaches in capturing very long temporal dependencies and achieving superior arousal/valence prediction.
IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) 2019
Supervised Contrastive Embeddings for Binaural Source Localization
Duowei Tang, Maja Taseska, and Toon van Waterschoot
Proposes a supervised contrastive manifold learning method that learns robust embeddings preserving binaural sound source spatial relationships.
Experience
AI / Speech and Audio Processing Algorithm Designer — Goodix Technology
Design efficient deep learning speech enhancement algorithms for the worldwide top-tier smartphones. Supervising and managing of internship projects.
Ph.D. Candidate — KU Leuven
Supervisor: Prof. dr. ir. Toon van Waterschoot, Prof. dr. Peter Kuppens, and Prof. dr. ir. Luc Geurts
Deep Learning for Audio/Speech Applications: A perspective on representation learning and sequence modelling.
Internship Researcher — UgenTec
Semi-supervised machine learning on partially labelled data, application to Polymerase Chain Reaction (PCR) data. Propose a semi-supervised model using k-means clustering and LSSVM.
Internship Researcher — NXP
Speaker recognition algorithms. Compare, analysis and test state-of-the-art GMM and iVector based speaker recognition algorithms.